Architectural Background
NUMA machines provide a linear address space, allowing all processors to directly address all memory. This feature exploits the 64-bit addressing available in modern scientific computers. The advantages over distributed memory machines include faster movement of data, less replication of data and easier programming. The disadvantages include the cost of hardware routers and the lack of programming standards for large configurations. FMS solves the programming standard issue by providing a set of programming tools that are portable across all NUMA architectures, as described below.Node of a NUMA machine
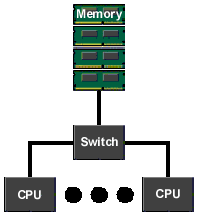 The fundamental building block of a NUMA machine is a Uniform Memory Access (UMA) region that we
will call a "node". Within this region, the CPUs share a common physical memory.
This local memory provides the fastest memory access for each of the CPUs on the node.
Modern processors contain many CPUs within the processor itself.
Multiple processors each having many CPUs can be configured as a node.
The fundamental building block of a NUMA machine is a Uniform Memory Access (UMA) region that we
will call a "node". Within this region, the CPUs share a common physical memory.
This local memory provides the fastest memory access for each of the CPUs on the node.
Modern processors contain many CPUs within the processor itself.
Multiple processors each having many CPUs can be configured as a node.
NUMA machine
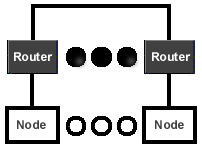 For larger configurations, multiple nodes are combined to form a NUMA machine.
When a processor on one node references data that is stored on another node, hardware routers
automatically send the data from the node where it is stored to the node where it is being
requested. This extra step in memory access results in delays, which can degrade performance.
Small to medium NUMA machines have only one level of memory hierarchy; data is either local or
remote. Larger NUMA machines use a routing topology, where delays are greater for nodes
further away.
For larger configurations, multiple nodes are combined to form a NUMA machine.
When a processor on one node references data that is stored on another node, hardware routers
automatically send the data from the node where it is stored to the node where it is being
requested. This extra step in memory access results in delays, which can degrade performance.
Small to medium NUMA machines have only one level of memory hierarchy; data is either local or
remote. Larger NUMA machines use a routing topology, where delays are greater for nodes
further away.
One design goal of a NUMA machine is to make the routers as fast as possible to minimize the difference between local and remote memory references.
The performance of an individual application depends on the number of nodes used. If only two nodes are used and the memory is placed randomly, there will be a 50% chance that memory references will be local. As the number of nodes increases, this probability decreases. The FMS Programming Tools described in the next section overcome the scaling issues associated with large NUMA architectures.
Programming
The goal for optimal programming of NUMA machines is to maximize references to local memory on the node while minimizing references to remote memory. FMS contains the following unique "hooks" into the operating system that provide the control necessary to achieve this goal:- Thread Binding.
The compute and I/O threads managed by FMS may be physically bound to specific processors or nodes. This is the first step necessary in establishing the affinity between executing threads and the physical memory they reference. - Memory Placement.
When FMS allocates memory, it may be explicitly placed on the processor's local node.
The Parallel Programming Tools available with FMS provide these same hooks for you to achieve optimal NUMA performance on the non-FMS part of your application. These tools provide a common portable interface across all NUMA machines.
Using FMS on NUMA machines
FMS contains a single Parameter NUMAFL which turns on or off all special NUMA features. By default, this Parameter is set off, leaving the placement of threads and memory up to the operating system. This provides the best setting when the machine is used in a multi-user environment to run a large number of jobs of different priorities.When NUMAFL is set, your application will explicitly control which CPUs are used and where allocated memory is placed. This setting provides the best performance when all or part of the machine may be dedicated to your application.
When operated in NUMA mode, the FMS Parameters MYCPU1 and MAXCPU control the starting and number of CPUs used. When the FMS Memory Management routines are called to allocate memory by a child thread, the memory is automatically placed on the node where the child thread is executing. When memory is allocated by the parent, it is distributed among all the nodes in a round-robin fashon using a stride of MAXLMD. Specifying a value of 0 for MAXLMD will result in FMS allocating all the memory on the parent's node.
These FMS Parameters provide all the control necessary for optimal NUMA performance, either within FMS or your application.
There are several reasons why a NUMA operating system will not automatically do the right thing all of the time. First, the operating system cannot anticipate the memory access patterns of your application. By default, memory is usually placed on the node which generates the first reference (first touch placement). If your application later enters a different phase with different access patterns, almost all of the memory references will probably be remote. Some attempts have been made to dynamically move data to the nodes generating the most references (page migration). However this is after the fact and generally gets out of phase with the current reference pattern, resulting in decreased rather than increased performance.
Second, if the system is oversubscribed (more jobs than processors), processors must be shared. Under these conditions, threads are generally assigned on the basis of processor availability, not on the placement of data which they will reference (which is unknown by the operating system). As a result, once a thread changes processors, most of the memory references will probably be remote.
When a system is freshly booted, all memory is available. The first job will have its choice of where to place the memory. The remaining jobs, however, will be restricted to the amount of memory currently available. A small job which requests lots of memory will spill over to adjacent nodes. The longer the system runs, the dirtier the memory system becomes, making it increasingly impossible for optimal memory placement.
The FMS NUMA programming tools described above solve all these problems by providing you with explicit control over thread and memory placement.